AtlasCV
Created on 23 Oct 2018
A CV-oriented solution for autonomously controlling a buggy.
Computer vision has been long held a strong utility for autonomous vehicles. CV is used to identify lane markers, cars, traffic lights, and many other unique objects on the road. By identifying these features, vehicles can decide how to act in a certain situation: should it turn left, should it turn right, should it move faster, should it stop?
We wish to bring a small part of CV's utility into the ever-growing field of robotic buggy. To do this, we will be implementing a vision-based controller for our RD18 autonomous platform, BabyBuggy.
Our pipeline is fairly straightforward, though the complexity is most certainly in the details. First, a convolutional network will be trained to perform image segmentation, the task of splitting an image into solid portions that identify different key areas in a scene. For our purpose, the network will distinguish between road and not road.
Then, with this segmented image, we will write a controller to steer BabyBuggy depending on its calculated position and offset from the sides of the road.
Our implementation will utilize an Intel D435 camera, important primarily for its cheap access to a global shutter. This drastically reduces the distortion we get from cheaper rolling shutter cameras. As a stretch goal, we are also planning to use state-of-the-art CV algorithms like YOLO and Mask-RCNN to perform real-time object detection.


@ovg
Oshadha Gunasekara

@zhengx
Zheng Xu

@xguan
Xinyu Guan

@blairc
Blair Chen

@sjaiswa2
Shreyan Jaiswal
| Part | Cost | Quantity | Total |
| Intel RealSense D435 | $209.99 | 1 | $209.99 |
| Global shutter stereo camera we will use for computer vision based navigation. | |||
| NRF24L01+ | $11.98 | 1 | $11.98 |
| RF Transceiver Modules for TOF distance calculations. | |||
| Camera Mount | $11.99 | 1 | $11.99 |
| Mount for the camera | |||
| Pro Micro | $20.89 | 1 | $20.89 |
| Pro Micro Microcontroller for communicating with NRF24L01+ | |||
| Project Totals: | 4 | $254.85 | |
| Track 1 Base Budget: | $250.00 | ||
| Preferred Vendor Budget Bonus: | $50.00 | ||
| Remaining Budget: | $45.15 | ||





Oshadha Gunasekara
15 Jan 2019, 8:39 p.m. EST
The team just had dinner!
Oshadha Gunasekara
15 Jan 2019, 5:45 p.m. EST
Blair Chen IS HERE!
Oshadha Gunasekara
15 Jan 2019, 2:03 p.m. EST
A neural network has been chosen to perform image segmentation. Our dataset is being manipulated to train properly on the model.
Oshadha Gunasekara
15 Jan 2019, 2:05 p.m. EST
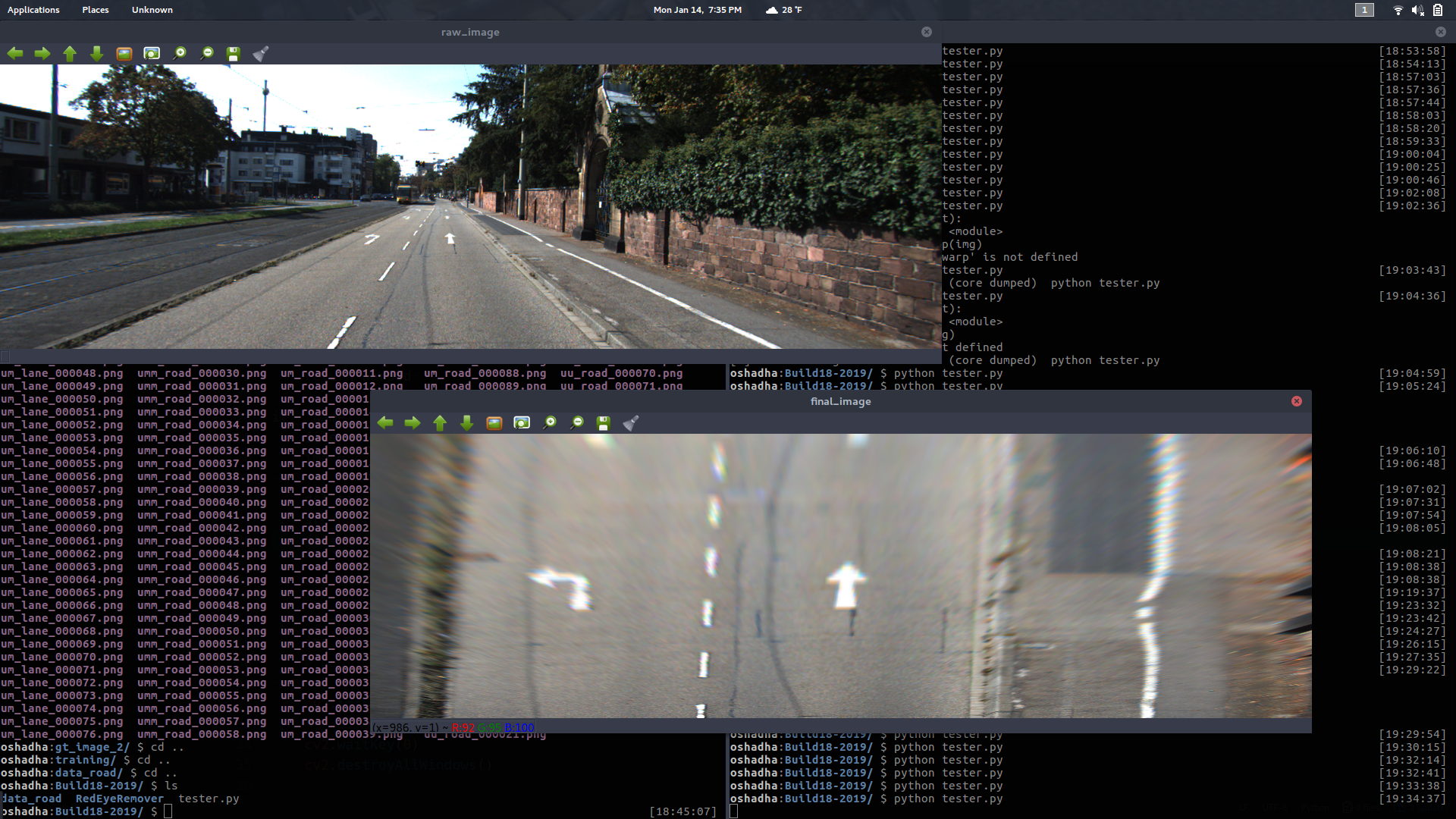
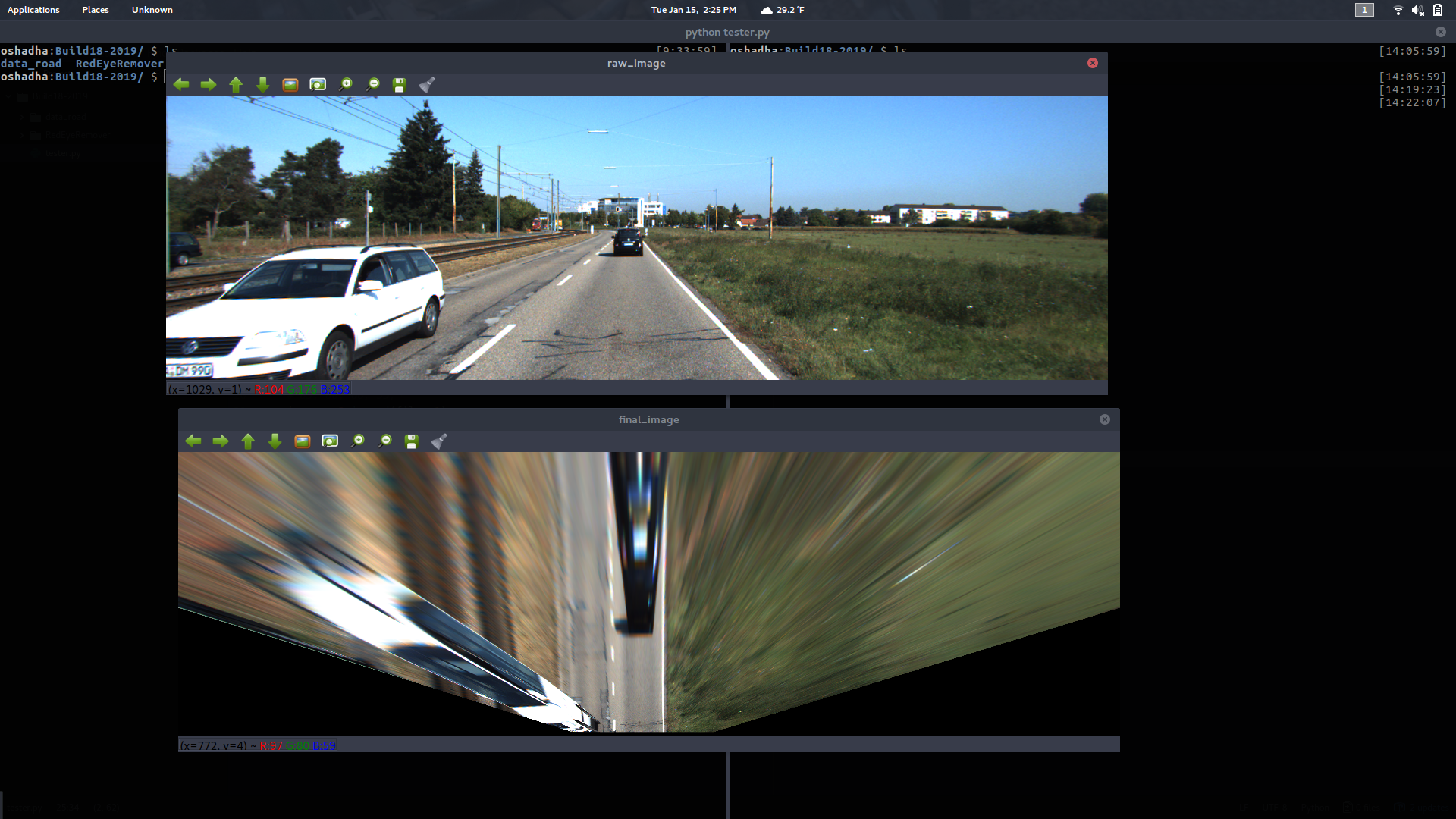
We are also working on transforming an image from standard car view to bird's eye view using OpenCV's perspective transform.
Oshadha Gunasekara
15 Jan 2019, 5:01 p.m. EST
Xinyu Guan is working on loading the images into more immediate memory to be used in training the network.
Oshadha Gunasekara
15 Jan 2019, 5:03 p.m. EST
For the network, we are using VGGNet with an additional deconvolution layer on top. The deconvolution layer is used to increase the resolution of the VGGNet network output to our desired output.
Oshadha Gunasekara
15 Jan 2019, 5:06 p.m. EST
Interesting note by Zheng Xu: When transforming perspective from driver perspective to bird's eye perspective, it's better to keep the top portion of the road constant while shrinking the bottom of the road. This helps us keep more detail in the original image.
Oshadha Gunasekara
15 Jan 2019, 5:40 p.m. EST
Shreyan Jaiswal is working on determining the curvature of the road given a perspective warped image.
Oshadha Gunasekara
15 Jan 2019, 5:41 p.m. EST
Oshadha Gunasekara, contrary to popular belief, is not just wasting time. He is working on determining a control method for the buggy given calculated lane/road lines.
Oshadha Gunasekara
15 Jan 2019, 9:18 p.m. EST
Having WiFi issues with the TX2 :O
Oshadha Gunasekara
16 Jan 2019, 7:13 p.m. EST
We were able to fix wifi issues with the TX2!
Oshadha Gunasekara
16 Jan 2019, 7:14 p.m. EST
Shane worked on training the neural while he was on a plane! What a baller! 😎😎😎
Oshadha Gunasekara
16 Jan 2019, 7:15 p.m. EST
Frank was able to capture some test bagfiles using the D435 camera today to test our CV pipeline.
Oshadha Gunasekara
16 Jan 2019, 7:16 p.m. EST
TEAM DINNER
Oshadha Gunasekara
16 Jan 2019, 8:54 p.m. EST
We can now use BOTH keyboard and mouse on the TX2 using the Dell Monitors! O:
Oshadha Gunasekara
16 Jan 2019, 10:06 p.m. EST
OpenCV is "somewhat" installing on the TX2!
Oshadha Gunasekara
17 Jan 2019, 12:37 p.m. EST
Most dependencies have been successfully installed on the TX2.
Oshadha Gunasekara
17 Jan 2019, 12:38 p.m. EST
On the CV side of things, we have fully integrated the D435 onto ROS and are able to run our perspective transform natively on ROS.
Oshadha Gunasekara
17 Jan 2019, 12:39 p.m. EST
Further, we are able to identify lane lines given a segmented image and calculate an approximate curvature of the road.
Oshadha Gunasekara
17 Jan 2019, 8:27 p.m. EST
FRANK GIVETH BLAIR THE NETWORK